高级数据结构(一)
对于一个大二开始打ACM的蒟蒻,也许太晚了.......但去试试总没错的
该内容实际上是我们班的算法优化理论与技术的课程,也是我对ACM的一段学习过程
除了学习之外,刷题也是必不可少的,少部分是老师布置外,其余都是在洛谷上刷的
一、树状数组
核心概念
1. 定义
树状数组是一种高效的前缀和 / 单点更新数据结构,核心是通过二进制拆分思想,将数组操作的时间复杂度优化至 $O(\log n)$,适用于频繁的单点修改 + 区间查询场景(仅支持前缀和类操作)。
2. 核心思想
利用数组下标(从 1 开始)的二进制特性,将数组划分为若干区间,每个节点 tree[i] 管理原数组中一段连续区间的和:
- 节点 i 的管辖范围长度:$lowbit(i) = i \& -i$(二进制最低位 1 对应的值);
- 例:$i=6$(二进制 110),$lowbit(6)=2$,
tree[6]管理 $a[5,6]$ 的和。
核心操作(模板代码)
以下为洛谷P3374【模板】树状数组1的代码
#include<bits/stdc++.h>
#define lowbit(x) (x)&-(x)
using namespace std;
typedef long long ll;
ll n,m,tree[500005]={0};
int main(){
cin>>n>>m;
for(int i=1;i<=n;i++){
ll v;cin>>v;
ll x=i;
while(x<=n){
tree[x]+=v;
x+=lowbit(x);
} //建立树状数组
}
for(int i=0;i<m;i++){
ll op,x,y;
cin>>op>>x>>y;
if(op==1){
while(x<=n){
tree[x]+=y;
x+=lowbit(x);
}//对单点修改
}
else {
x--;
ll sum1=0,sum2=0;
while(y>0){
sum1+=tree[y];
y-=lowbit(y);
}
while(x>0){
sum2+=tree[x];
x-=lowbit(x);
}
cout<<sum1-sum2<<endl;//求区间和
}
}
return 0;
}
对树状数组的进一步拓展[1]
1. 二维区间修改
二维树状数组是对一维树状数组的扩展,用于处理二维数组的前缀和、区间查询和修改。它通过两个维度上的二进制索引拆分,实现高效操作(时间复杂度 $O(\log n \log n)$)。
核心思想
- 二维树状数组
tree[x][y]管理二维数组中以 (x, y) 为右下角的矩形区域的和。 - 使用
lowbit函数在两个维度上进行更新和查询。 - 支持点更新 + 区间查询,或通过差分思想实现区间更新 + 点查询。
二维的“区间修改+区间查询”是一维“区间修改+区间查询”的扩展,方法和推导过程类似。
定义
定义一个二维差分数组 $D[i][j]$,它与矩阵元素 $a[c][d]$ 的关系为
它们同样满足“差分是前缀和的逆运算”。
用二维树状数组实现 $D[i][j]$,编码见示例代码中的 update() 和 sum() 函数。进行区间修改时,在 update() 函数中,每次第 $i$ 行减少 $\text{lowbit}(i)$,第 $j$ 列减少 $\text{lowbit}(j)$,复杂度为 $O(\log_2 n \log_2 m)$。
二维区间查询
查询以 $(a,b)$ 和 $(c,d)$ 为顶点的矩阵区间和,对照图 4.10 的阴影部分,有
问题转换为计算 $\sum_{i=1}^{n}\sum_{j=1}^{m} a[i][j]$,根据它与差分数组 $D$ 的关系进行变换,有
这是 4 个二维树状数组。
2.关于偏序[1:1]
关于偏序问题,以一维、二维、三维偏序问题为例,介绍如下:
(1) 一维偏序(逆序对):给定数列 \(a\),求满足 \(i<j\) 且 \(a_i>a_j\) 的二元组 \((i,j)\) 的数量。
(2) 二维偏序:给定 \(n\) 个点的坐标,求出满足 \(x_i<x_j\)、\(y_i<y_j\) 的二元组 \((i,j)\) 的数量。
(3) 三维偏序:给定 \(n\) 个点的坐标,求满足 \(x_i<x_j\)、\(y_i<y_j\)、\(z_i<z_j\) 的二元组 \((i,j)\) 的数量。
以下是洛谷P1908 逆序对的题
猫猫 TOM 和小老鼠 JERRY 最近又较量上了,但是毕竟都是成年人,他们已经不喜欢再玩那种你追我赶的游戏,现在他们喜欢玩统计。
最近,TOM 老猫查阅到一个人类称之为“逆序对”的东西,这东西是这样定义的:对于给定的一段正整数序列,逆序对就是序列中 $a_i>a_j$ 且 $i<j$ 的有序对。知道这概念后,他们就比赛谁先算出给定的一段正整数序列中逆序对的数目。注意序列中可能有重复数字。
#include<bits/stdc++.h>
#define lowbit(x) (x)&-(x)
typedef long long ll;
using namespace std;
struct node{
ll num,index;
};
bool cmp(node a,node b){
if(a.num!=b.num)return a.num<b.num;
else return a.index<b.index;
}
int main(){
ll n,a[500005],tree[500005]={0};
cin>>n;
node op[500005];
for(int i=1;i<=n;i++){
cin>>op[i].num;
op[i].index=(ll)i;
}
sort(op+1,op+n+1,cmp);
for(int i=1;i<=n;i++){
a[op[i].index]=(ll)i;
}//离散化,对于相同的数,原序列在前的排前面
ll sum=0;
for(int i=1;i<=n;i++){
ll x=a[i],p=0;
while(x<=n){
tree[x]++;
x+=lowbit(x);
}x=a[i];
while(x>0){
p+=tree[x];
x-=lowbit(x);
}
sum+=(ll)i-p;
}//对于正序1,2,...,n位置的数为0,到第i个数a[i],使得正序中的a[i]的位置为1,则累加1~a[i]位置的数总和则为第i个数计算出的逆序
cout<<sum;
return 0;
}
二、线段树
线段树的核心概念
线段树(Segment Tree)是一种基于分治思想的二叉树结构,用于高效处理「区间查询」和「单点 / 区间更新」问题。它将一个长度为 n 的数组(区间)拆分为若干个不重叠的子区间(线段),每个节点对应一个子区间,叶子节点对应数组的单个元素。
核心特点:
- 结构:完全二叉树(可用数组模拟),每个节点存储对应区间的聚合信息(如和、最大值、最小值、乘积等);
- 效率:区间查询、单点更新的时间复杂度为 O(logn),区间更新(懒标记优化)也为 O(logn);
- 适用场景:需要频繁对数组进行「区间查询」和「更新」的场景(如求区间和、区间最大值、区间修改等)。
核心操作(具体代码)
已知一个数列 $\{a_i\}$,你需要进行下面两种操作:
- 将某区间每一个数加上 $k$。
- 求出某区间每一个数的和。
#include<bits/stdc++.h>
using namespace std;
// 常量定义:数组最大长度(1e5+7),防止越界
const int N=1e5+7;
// 类型别名:将long long简化为ll,方便书写
typedef long long ll;
// 全局变量声明
ll a[N]; // 原始数组,存储初始数据
ll tree[N*4]; // 线段树数组,大小为4*N(线段树标准空间)
ll tag[N*4]; // 懒标记数组,用于区间更新的延迟操作
ll n,m; // n:数组长度,m:操作次数
/**
* 构建线段树
* @param p 当前节点编号(根节点为1)
* @param x 当前节点覆盖的区间左端点
* @param y 当前节点覆盖的区间右端点
*/
void build(ll p,ll x,ll y){
// 递归终止条件:叶子节点(区间长度为1)
if(x==y){
tree[p]=a[x]; // 叶子节点值等于原始数组对应位置的值
return ;
}
// 计算区间中点,避免溢出(等价于(x+y)/2)
ll mid=x+(y-x)/2;
// 递归构建左子树(节点编号2p,区间[x,mid])
build(p<<1,x,mid);
// 递归构建右子树(节点编号2p+1,区间[mid+1,y])
build(p<<1|1,mid+1,y);
// 父节点值 = 左子树值 + 右子树值(区间和)
tree[p]=tree[p<<1]+tree[p<<1|1];
return ;
}
/**
* 给当前节点添加懒标记,并更新当前节点的区间和
* @param p 当前节点编号
* @param x 当前节点覆盖的区间左端点
* @param y 当前节点覆盖的区间右端点
* @param d 区间每个元素需要增加的值
*/
void addtag(ll p,ll x,ll y,ll d){
tag[p]+=d; // 记录懒标记(延迟更新)
tree[p]+=d*(y-x+1); // 更新当前节点的区间和:每个元素加d,共(y-x+1)个元素
}
/**
* 下传懒标记(将当前节点的标记传递给左右子节点)
* @param p 当前节点编号
* @param x 当前节点覆盖的区间左端点
* @param y 当前节点覆盖的区间右端点
*/
void push_down(ll p,ll x,ll y){
// 只有当懒标记不为0时,才需要下传
if(tag[p]){
ll mid=x+(y-x)/2;
// 下传标记到左子节点
addtag(p<<1,x,mid,tag[p]);
// 下传标记到右子节点
addtag(p<<1|1,mid+1,y,tag[p]);
// 清除当前节点的懒标记(已下传)
tag[p]=0;
}
}
/**
* 区间更新:将区间[l,r]内的所有元素加d
* @param p 当前节点编号
* @param l 待更新区间的左端点
* @param r 待更新区间的右端点
* @param x 当前节点覆盖的区间左端点
* @param y 当前节点覆盖的区间右端点
* @param d 每个元素需要增加的值
*/
void update(ll p,ll l,ll r,ll x,ll y,ll d){
// 情况1:当前节点区间完全包含在待更新区间内(直接更新+打标记)
if(l<=x&&y<=r){
addtag(p,x,y,d); // 给当前节点加标记,更新区间和
return ;
}
// 情况2:当前节点区间与待更新区间部分重叠(需要下传标记)
push_down(p,x,y); // 先下传懒标记,保证子节点值正确
ll mid=x+(y-x)/2;
// 左子节点区间与待更新区间有交集,递归更新左子树
if(l<=mid)update(p<<1,l,r,x,mid,d);
// 右子节点区间与待更新区间有交集,递归更新右子树
if(mid<r)update(p<<1|1,l,r,mid+1,y,d);
// 更新当前节点的区间和(子节点更新后,父节点需要重新计算)
tree[p]=tree[p<<1]+tree[p<<1|1];
return ;
}
/**
* 区间查询:查询区间[l,r]的和
* @param l 待查询区间的左端点
* @param r 待查询区间的右端点
* @param p 当前节点编号
* @param x 当前节点覆盖的区间左端点
* @param y 当前节点覆盖的区间右端点
* @return 区间[l,r]的和
*/
ll query(ll l,ll r,ll p,ll x,ll y){
// 情况1:当前节点区间完全包含在待查询区间内(直接返回当前节点值)
if(l<=x&&y<=r)return (ll)tree[p];
// 情况2:当前节点区间与待查询区间部分重叠(需要下传标记)
ll mid=x+(y-x)/2,ans=0;
push_down(p,x,y); // 下传标记,保证子节点值正确
// 左子节点区间与待查询区间有交集,递归查询左子树
if(l<=mid)ans+=query(l,r,p<<1,x,mid);
// 右子节点区间与待查询区间有交集,递归查询右子树
if(mid<r)ans+=query(l,r,p<<1|1,mid+1,y);
// 返回查询结果
return ans;
}
int main(){
// 输入数组长度n和操作次数m
scanf("%lld %lld",&n,&m);
// 输入原始数组的n个元素
for(ll i=1;i<=n;i++)scanf("%lld",&a[i]);
// 构建线段树(根节点1,覆盖区间[1,n])
build(1,1,n);
// 处理m次操作
for(ll i=0;i<m;i++){
ll op;
// 输入操作类型:1=区间更新,2=区间查询
scanf("%lld",&op);
if(op==1){
// 区间更新:输入待更新区间[x,y]和增加值k
ll x,y,k;
scanf("%lld %lld %lld",&x,&y,&k);
// 调用update函数,更新区间[x,y],每个元素加k
update(1,x,y,1,n,k);
}
else {
// 区间查询:输入待查询区间[x,y]
ll x,y;
scanf("%lld %lld",&x,&y);
// 调用query函数,查询区间[x,y]的和并输出
printf("%lld\n",query(x,y,1,1,n));
}
}
return 0;
}
其他
1.LCA - Lowest Common Ancestor
树是一种简单无向图,图中任意两个节点仅被一条边连接。所有连通无环无向图都是一棵树。
最近公共祖先(LCA)是图论和计算机科学中的一个概念。设 $\text{T}$ 是一个有 $N$ 个节点的有根树,树上有两个节点 $v$ 和 $w$,而这两个节点的最近公共祖先是 $u$,那么 $u$ 是 $v$ 和 $w$ 在 $\text{T}$ 上的祖先(允许自己是自己的祖先),且在满足上面的前提的所有节点中,其在 $T$ 上的高度最低。
——摘自维基百科
现在,你需要对于给定的树 $\text{T}$ 以及两个节点 $v$ 和 $w$,求出它们的最近公共祖先。
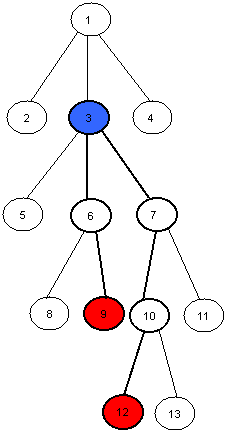
如下图所示,图中 $9$ 号节点与 $12$ 号节点的最近公共祖先为 $3$ 号节点。
解法一(树剖)
- 轻重链剖分是一种将树形结构拆解为线性链的预处理算法,核心是把一棵树分割成若干条不相交的「链」(分为重链和轻链),使得任意两点间的路径都能被拆成 $O(logn)$ 条连续的链。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int f[1005],n,m,root,dep[1005]={0},line[1005],w[1005];//f[x]表示x的父节点,dep[x]表示x的深度,line[x]表示x所在树链的最顶节点,w[x]为子树x大小
vector<vector<int>>edge(1005);
void swap(int *a,int *b){
int t=*a;
*a=*b;
*b=t;
}
void dfs(int x){
dep[x]=dep[f[x]]+1;
for(int i=0;i<edge[x].size();i++){
if(edge[x][i]!=f[x])
{
f[edge[x][i]]=x;
dfs(edge[x][i]);
w[x]+=w[edge[x][i]]+1;
}
}
if(edge[x].size()==1)w[x]=1;
return ;
}//求每个点的深度与父节点
void dfs1(int x,int highest){
line[x]=highest;int mx=0,l=0;
for(int i=0;i<edge[x].size();i++){
if(w[edge[x][i]]>mx&&edge[x][i]!=f[x]){
mx=w[edge[x][i]];
l=i;
}
}
for(int i=0;i<edge[x].size();i++){
if(edge[x][i]!=f[x]){
if(i==l){
dfs1(edge[x][i],highest);
}
else dfs1(edge[x][i],edge[x][i]);
}
}
return ;
} //求树链的顶端
int find(int x,int y){
while(line[x]!=line[y]){
if(dep[line[x]] < dep[line[y]])swap(&x,&y);
x=f[line[x]];
}
if(dep[x]<dep[y])return x;
else return y;
}//求LCA
int main(){
cin>>n>>m>>root;
for(int i=1;i<n;i++){
int x,y;cin>>x>>y;
edge[x].push_back(y);
edge[y].push_back(x);
}
dfs(root);
dfs1(root,root);
while(m--){
int x,y;
cin>>x>>y;
cout<<find(x,y)<<endl;
}
return 0;
}
解法二(倍增法)
- 预处理出每个节点「跳 $2⁰、2¹、2²…2^{logn}$ 步」能到达的祖先,找第 k 个祖先时,把 $k$拆成二进制(比如 $k=5=4+1=2²+2⁰$),只需跳 2 步(先跳 4 步,再跳 1 步),总步数是 $O (logn)$。
- 定义 $go[i][j]$:表示节点 $i$ 向上跳 $2ʲ$ 步到达的祖先节点($j$ 从 0 开始)。
- 边界条件:$go[i][0]$ 是节点 i 的直接父节点(跳 1 步,2⁰=1);
- 状态转移:$go[i][j] = go[go[i][j-1]][j-1]$(跳 $2ʲ$ 步 = 先跳 $2^{j-1}$ 步,再跳 $2^{j-1}$ 步)。
#include<bits/stdc++.h>
using namespace std;
const int N=5e5;
int go[N][20]={0},n,m,root,f[N]={0},dep[N]={0};
vector<int> edge[N+10];
void dfs(int x){
dep[x]=dep[f[x]]+1;
for(int j=0;j<20;j++){
if(!j)go[x][j]=f[x];
else go[x][j]=go[go[x][j-1]][j-1];
}
for(int i=0;i<edge[x].size();i++){
if(edge[x][i]!=f[x]){
f[edge[x][i]]=x;
dfs(edge[x][i]);
}
}
}//寻找父节点,每个节点的深度,以及初始化go[][]
int find(int x,int y){
if(dep[x]<dep[y])swap(x,y);
for(int i=19;i>=0;i--){
if(dep[go[x][i]]>=dep[y])x=go[x][i];
}
if(x==y)return x;
for(int i=19;i>=0;i--){
if(go[x][i]!=go[y][i]){
x=go[x][i];
y=go[y][i];
}
}
return f[x];
}//用倍增法找到LCA
int main(){
cin>>n>>m>>root;
for(int i=1;i<n;i++){
int x,y;
scanf("%d %d",&x,&y);
edge[x].push_back(y);
edge[y].push_back(x);
}
dfs(root);
for(int i=0;i<m;i++){
int x,y;cin>>x>>y;
printf("%d\n",find(x,y));
}
return 0;
}